대양변동과 한반도 폭염예측모형
- 조회 : 5248
- 등록일 : 2019-02-01
대양변동과 한반도 폭염예측모형
해양순환·기후연구센터 권민호 책임연구원
폭우와 열파와 같은 극한 자연현상이 사회에 미치는 파급효과는 매우 크다. 남한의 관측 기온은 지구온난화와 관련하여 꾸준히 상승하고 있으며, 이와 관련하여, 폭염을 포함하는 극한 기온과 관련된 현상들이 더욱 빈번히 나타나고 있다. 지역적인 것뿐만 아니라 전세계적으로도 지난 세기 동안 극한 기상현상들이 더욱 빈번히 나타나고 있으며, 이에 따라 그 관심도도 크게 증가하고 있다. 또한 기상청 보고서에 따르면, 다른 기상재해에 비하여 폭염에 의한 사상자가 월등히 높은 것으로 조사되었다. 전세계적으로 대부분의 현업예측기관에서 폭염에 대한 예측시스템은 구축되어 있지 않다. 기상청에서도 계절평균 기후변동에 대한 예측에는 많은 인적·물적 자원을 투자하고 있지만, 폭염에 대한 사회적 경제적 파급효과가 매우 큼에도 불구하고 관련 분야의 현업예측시스템은 아직 구축되어 있지 않다. 폭염과 같은 극한 현상들을 직접 예측하는 것은 현재 과학기술로 거의 불가능하기 때문이다. 폭염 현상을 개별적으로 예측하는 것은 어렵지만, 계절 전체에서 확률적으로 폭염을 예측하는 것은 어느 정도 가능할 수 있다. 여기서는 한반도 지역에 대하여 폭염을 확률적으로 예측하는 방법론을 소개하고자 한다.
극한 현상이 일어나는 빈도 및 강도는 확률변수(random variable)에 가깝기 때문에 매우 예측하기가 어렵지만, 정규분포를 따르는 확률변수라고 하더라도 일정한 구간에 대하여 가장 큰 값을 뽑아서 새로운 자료세트를 만들게 되면, 이 새로운 자료는 GEV(Generalized Extreme Value) 분포를 따르는 것으로 알려져 있다. 즉, 정규분포를 갖는 확률변수, 에 대하여, 특정 구간 혹은 블록(block)에서의 최대값을 이라고 하면, 충분한 수의 에 대하여 확률변수, Z1, Z2, ... 에 대하여, 특정 구간 혹은 블록(block)에서의 최대값을 Ym 이라고 하면, 충분한 수의 Ym 에 대하여 확률변수, Y는 다음과 같은 확률밀도함수를 갖는다.

여기서, 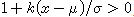 를 만족한다. 이 확률분포를 GEV 분포라고 한다. 이 분포는 세 개의 매개변수가 있다. 그들은 위치변수(location parameter;
를 만족한다. 이 확률분포를 GEV 분포라고 한다. 이 분포는 세 개의 매개변수가 있다. 그들은 위치변수(location parameter; 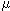 ) , 규모변수(scale parameter;
) , 규모변수(scale parameter; 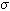 ), 그리고 모양변수(shape parameter;
), 그리고 모양변수(shape parameter;  )이다. 관측자료에 대하여 이 세 매개변수를 적합(fitting)시키면, 관측자료에 대한 GEV 분포를 얻을 수 있다. 그림 1은 서울 지역 일최고 기온에 대하여 GEV 분포에 적합시킨 결과를 보인다. 표본의 수가 충분히 큰 경우에 위 매개변수를 추정하기 위하여 GEV 확률밀도함수를 최대로 만드는 수치적인 방법이 이용된다. 이를 최대우도추정법(Maximum likelihood estimated method)이라고 한다.
)이다. 관측자료에 대하여 이 세 매개변수를 적합(fitting)시키면, 관측자료에 대한 GEV 분포를 얻을 수 있다. 그림 1은 서울 지역 일최고 기온에 대하여 GEV 분포에 적합시킨 결과를 보인다. 표본의 수가 충분히 큰 경우에 위 매개변수를 추정하기 위하여 GEV 확률밀도함수를 최대로 만드는 수치적인 방법이 이용된다. 이를 최대우도추정법(Maximum likelihood estimated method)이라고 한다.
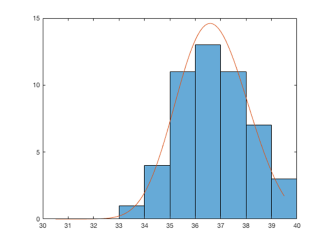
그림 1 서울 일최고기온의 히스토그램(파란색)과 자료에 적합시킨 GEV 분포(오렌지색)
일최고기온은 일반적으로 항상성(stationarity)을 가정할 수 없으며, 각 매개변수들은 시간에 따라 변한다. 기후값 관점에서 한반도의 일최고기온은 연중 8월초에 최고값을 갖고, 6월과 7월은 상대적으로 낮은 값을 갖는다. 그러나 특정해에는 일최고기온의 연중 최고값이 7월이나 9월에 나타나기도 한다. 즉, 일반적으로 일최고기온의 분포는 해마다 다르다고 할 수 있다. 특정해의 GEV 분포를 구하는 것은 표본수의 부족으로 어렵지만 엘니뇨와 같은 특정한 조건은 여러 해가 있으므로 상대적으로 많은 표본에 대하여 GEV 분포를 구하는 것은 가능하다. 엘니뇨 조건과 같이 한반도 여름철 폭염에 영향을 주는 여러 기후변동 인자들이 있다. 열대 동태평양의 해양 변동이 엘니뇨/라니냐뿐만 아니라 지구온난화와 같은 기후변화, 열대 인도양 해양 변동과 관련된 인도몬순 변동 등도 한반도 여름철 폭염에 큰 영향을 준다. 그림 2는 그 예로서 엘니뇨 빠른 전이와 느린 전이에 대한 GEV 분포의 뚜렷한 차이를 보이고 있다. 여기서 엘니뇨 느린 전이는 이전 겨울철이 엘니뇨이고, 그 다음 여름철에도 엘니뇨인 경우로 정의되고, 엘니뇨 빠른 전이는 이전 겨울철이 엘니뇨이지만, 그 다음 여름철에는 엘니뇨가 아닌 경우로 정의된다. 즉, 이전 겨울철에 엘니뇨였고, 올해 여름철에 라니냐가 예상이 된다면, 올해 폭염이 발생할 확률이 크게 높아진다는 것이다. 만약, 엘니뇨/라니냐와 같은 해양 변동을 계절규모에서 예측할 수 있다면, 한반도 폭염의 확률분포를 예측할 수 있다. GEV 분포 매개변수 변동에 영향을 주는 기후적 인자는 비단 엘니뇨/라니냐 뿐은 아니다. 일반적으로 현재까지 알려진 한반도 일최고기온에 영향을 주는 기후변동 인자는 다음과 같다.
1) 지난 겨울 엘니뇨/라니냐
2) 여름철 엘니뇨/라니냐
3) 엘니뇨의 느린 전환
4) 엘니뇨의 빠른 전환
5) 북서태평양 아열대 고기압 변동
6) 지구순환 원격상관(Circumglobal Teleconnection; CGT) 모드
7) 지구온난화
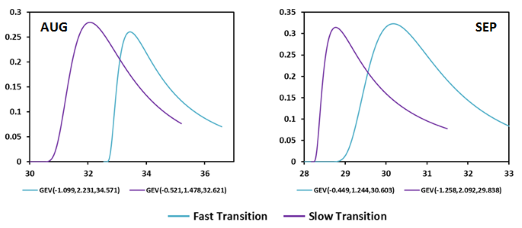
그림 2 서울 일최고기온에 대하여 빠른 엘니뇨 전이와 느린 엘니뇨 전이에 대한 GEV 확률분포
예측모형을 구성하기 위해서는 예측인자와 예측 대상이 되는 예측변수가 필요하다. 예측변수는 한반도 일최고기온에 대한 GEV 분포의 세 매개변수이고, 예측인자는 위에서 제시된 엘니뇨/라니냐와 같은 경년변동을 갖는 기후모드이다. 보통 예측인자와 예측변수를 통계적으로 적합시키기 위해서는 다중선형회귀모형(multiple linear regression model)이 많이 이용되지만, 위와 같이 예측인자와 예측변수가 모두 범주형 변수일 때는 새로운 통계적 적합방법이 필요하다. 이 경우 결정트리모델(decision tree model)이 이용될 수 있다. 결정트리모델의 예를 그림 3에 보인다. 그림 3은 위에서 제시된 기후인자들과 GEV 분포 매개변수 중 규모매개변수 사이의 적합결과를 보인다. 그림 3에 제시된 결정트리모델에 따르면, 여러 예측인자 중 여름철 엘니뇨 감시지역 변수가 양의 값이면, 규모매개변수가 음수가 된다. 반면, 여름철 엘니뇨 변수가 음의 값이면, 기후 예측인자 중 하나인 CGT 변수에 따라 결과가 달라지는데, 만약 CGT가 양이면 규모매개변수는 음이 되고, CGT가 양이면 규모매개변수는 양이 된다.
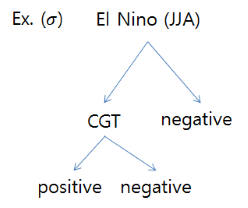
그림 3 결정트리 모델의 예
결정트리 모델의 상위 요소가 어떤 예측인자인지 결정하기 위하여 ID3(Iterative Dichotomiser3) 알고리즘이 이용될 수 있다. ID3 알고리즘은 자료가 섞여 있는 정도를 구하고, 그 정도가 가장 낮은 예측인자를 상위 요소로 결정하는 방법이다.
결정트리모델을 이용하여 자료를 적합시키고, 특정한 해에 대하여 예측한 결과를 그림 4에 보인다. 검정색 실선은 기후값을 보이고, 적색과 청색은 각각 2016년과 1991년의 예측값을 보인다. 2016년의 경우 좌측 꼬리(tail)은 상대적으로 변동이 적지만, 우측 꼬리는 우측으로 길게 늘어진 분포를 보이는데, 이는 상대적으로 더 극한 기온이 나타날 확률이 높다는 것을 의미한다. 반대로, 1991년의 경우 극한 기온의 나타날 확률이 상대적으로 낮다는 것을 나타낸다. 1991년의 경우에서 좌측 꼬리는 상대적으로 변동이 적은데, 이는 높은 극한기온의 경년변동은 크지만, 낮은 극한기온의 경년변동은 작다는 것을 나타낸다.
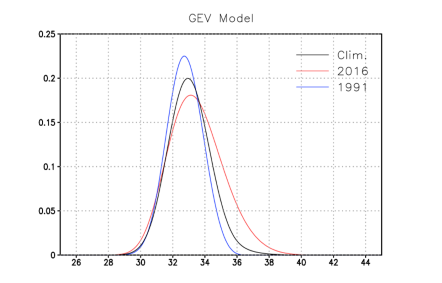
그림 4?GEV 확률분포모형을 이용한 8월 한반도 일최고기온의 1991년과 2016년 예측값, 그리고 기후값의 확률밀도함수
확률분포모형이기 때문에 모형의 정확도를 직접적으로 평가하기는 어렵지만, 관측 자료를 이용해 어느 정도 간접적으로 평가할 수 있다. 그림 5는 한반도 관측소 일최고기온 중 상위 90% 이상의 값(90 퍼센타일 기온)이 나타나는 날 수를 나타낸다. 그림에서 보이듯이 1991년에는 폭염이 나타나는 날수가 거의 없지만, 2016년에는 거의 모든 관측소에서 폭염 발생 일수가 현저히 높게 나타난다. 이 두 해 뿐 아니라 이 예측을 관측 모든 해로 확장하여 예측성을 구하면, 적중률이 약 75%가 된다. Heidke 성능점수는 약 0.36이다.
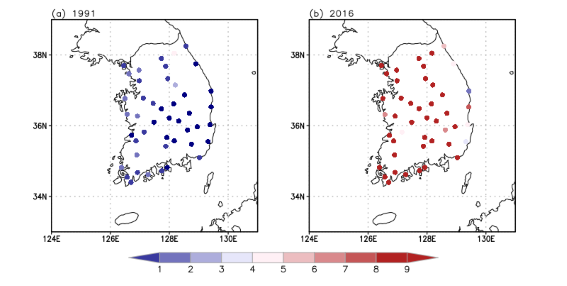
그림 5 (a) 1991년과 (b) 2016년의 한반도 주요 관측소 일최고기온 중 상위 90% 이상의 값이 나타나는 날
결정트리모형을 통한 한반도 폭염 확률예측모형은 사용된 자료 기간 내에서는 통계모형의 특성상 잘 맞지만, 실제로 예측에 적용이 되면, 그 예측성은 더 떨어질 가능성이 있다. 위 방법론에서는 예측인자로 소수의 대양 변동 인자를 고려하였는데, 모형의 예측성을 향상시키기 위해서는 새로운 예측인자 발굴이 요구된다. 또한, 변화하는 기후시스템의 한반도 영향 즉 빙권, 대양간 상호작용, 온실기체에 의한 기후변화에 대한 한반도 영향에 대한 이해가 필요하다.
한반도 기후 예측-방제시스템은 국민건강증진, 의료산업발달, 이상기후 대비 및 자연재해에 대한 피해를 경감시킨다. 위에서 제시된 한반도 폭염을 위한 계절규모의 확률예측모형은 산업 수요예측을 통해 해당 산업의 막대한 이익을 이끌 수 있을 뿐 아니라 위와 같이 예측-방제시스템의 한 부분으로서 다양한 분야에 기여할 것으로 기대된다.